| word2vec模型训练保存加载及简单使用 | 您所在的位置:网站首页 › negative sentence怎么读 › word2vec模型训练保存加载及简单使用 |
word2vec模型训练保存加载及简单使用
|
目录 word2vec模型训练保存加载及简单使用 一 word2vec简介 二、模型训练和保存及加载 模型训练 模型保存和加载 模型的增量训练 三、模型常用API 四、文本相似度计算——文档级别 word2vec模型训练保存加载及简单使用 一 word2vec简介word2vec是google开源的一款用于词向量计算的工具。可以这样理解word2vec,它是一个计算词向量的工具,也是一种语言算法模型。它的原理大致就是通过背后的CBow和skip-gram模型进行相应的计算,然后得出词向量。 本文的目的主要是介绍如何训练和使用word2vec来完成相应的NLP任务,这里不涉及到原理。使用的包是:gensim 二、模型训练和保存及加载 模型训练首先看看要用到的类: def __init__(self, sentences=None, size=100, alpha=0.025, window=5, min_count=5, max_vocab_size=None, sample=1e-3, seed=1, workers=3, min_alpha=0.0001, sg=0, hs=0, negative=5, cbow_mean=1, hashfxn=hash, iter=5, null_word=0, trim_rule=None, sorted_vocab=1, batch_words=MAX_WORDS_IN_BATCH, compute_loss=False, callbacks=()):主要关注的就是 sentences、size、window、min_count这几个参数。 sentences它是一个list,size表示输出向量的维度。 window:当前词与预测次在一个句子中最大距离是多少。 min_count:用于字典阶段,词频少于min_count次数的单词会被丢弃掉,默认为5 在训练模型之前,要对收集的预料进行分词处理,同时也要进行停用词的处理。在对数据进行预处理之后就可以训练我们的词向量了。训练的方式,从代码实现角度看,有两种,如下: from gensim.models import KeyedVectors,word2vec,Word2Vec import jieba import multiprocessing def stopwordslist(): stopwords = [ line.strip() for line in open('stopword.txt','r').readlines()] return stopwords if __name__ == '__main__': sentences_list = [ '详细了解园区规划,走访入驻企业项目,现场察看产品研发和产业化情况。他强调,', '要坚持规划先行,立足高起点、高标准、高质量,科学规划园区组团,提升公共服务水平,', '注重产城融合发展。要增强集聚功能,集聚产业、人才、技术、资本,加快构建从基础研究、', '技术研发、临床实验到药品生产的完整产业链条,完善支撑产业发展的研发孵化、成果转化、', '生产制造平台等功能配套,推动产学研用协同创新,做大做强生物医药产业集群。唐良智在调研', '中指出,我市生物医药产业具有良好基础,但与高质量发展的要求相比,在规模、结构、创新能力', '等方面还存在不足。推动生物医药产业高质量发展,努力培育新兴支柱产业,必须紧紧依靠创新创业', '创造,着力营造良好发展环境。要向改革开放要动力,纵深推进“放管服”改革,用好国际国内创新资源,', '大力引进科技领军人才、高水平创新团队。要坚持问题导向,聚焦企业面临的困难和问题,把握生物医药产业', '发展特点,精准谋划、不断完善产业支持政策,切实增强企业获得感。要精准服务企业,构建亲清新型政商关系,', '以高效优质服务助力企业发展', '2018年我省软件和信息服务业发展指数为67.09,'] #加载停用词表 stopwords = stopwordslist() sentences_cut = [] #结巴分词 for ele in sentences_list: cuts = jieba.cut(ele,cut_all=False) new_cuts = [] for cut in cuts: if cut not in stopwords: new_cuts.append(cut) sentences_cut.append(new_cuts) print(sentences_cut) #分词后的文本保存在data.txt中 with open('data.txt','w') as f: for ele in sentences_cut: ele = ele + '\n' f.write(ele) #可以用BrownCorpus,Text8Corpus或lineSentence来构建sentences,一般大语料使用这个 sentences = list(word2vec.LineSentence('data.txt')) # sentences = list(word2vec.Text8Corpus('data.txt')) # 小语料可以不使用 # sentences = sentences_cut print(sentences) #训练方式1 model = Word2Vec(sentences,size = 256, min_count=1, window=5,sg=0,workers=multiprocessing.cpu_count()) print(model) #训练方式2 #加载一个空模型 model2 = Word2Vec(size=256,min_count=1) # 加载词表 model2.build_vocab(sentences) # 训练 model2.train(sentences, total_examples=model2.corpus_count, epochs=10) print(model2) 模型保存和加载模型保存可以有很多种格式,根据格式的不同可以分为2种,一种是保存为.model的文件,一种是非.model文件的保存。我常用的保存格式是.model和.vector直接上代码和结果: # 方式一 model.save('word2vec.model') # 方式二 model2.wv.save_word2vec_format('word2vec.vector') model2.wv.save_word2vec_format('word2vec.bin')注意使用的API不同,一个是model.save() 一个是 model.wv.save_word2vec_format()。结果如图:.vector和.bin文件直接可以用txt打开可视,它们的内存占用要少一些,加载的时间要多一点。
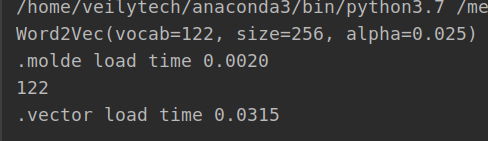
模型加载,对比如下: #加载方式1 t1 = time.time() model = Word2Vec.load('word2vec.model') t2 = time.time() print(model) print(".molde load time %.4f"%(t2-t1)) #加载方式2 t1 = time.time() model = KeyedVectors.load_word2vec_format('word2vec.vector') t2 = time.time() print(len(model.vectors)) print(".vector load time %.4f" % (t2 - t1))这两种方式的加载在获取词向量的时候应该是差别不大,区别就是.model可以继续训练,.vector的文件不能继续训练。加载速度也可以见,前者比后者快很多。前者时间为0.0020秒后者0.03秒,相差十多倍。
模型训练以后,模型中用到的词已经确定下来了,一般都会存在这样的场景,模型训练以后,会有新的语料,也就存在新词,这个时候新词用word2vec就得不到词向量,会报ovo(貌似这样的,反正就是out vacbuary)的错误。那么就需要重新训练模型,gensim就提供了一个很好的机制,就是增量训练,新词不用和旧词全部一起训练。 model = Word2Vec.load('word2vec.model') print(model) new_sentence = [ '我喜欢吃苹果', '大话西游手游很好玩', '人工智能包含机器视觉和自然语言处理' ] stopwords = stopwordslist() sentences_cut = [] #结巴分词 for ele in new_sentence: cuts = jieba.cut(ele,cut_all=False) new_cuts = [] for cut in cuts: if cut not in stopwords: new_cuts.append(cut) sentences_cut.append(new_cuts) #增量训练word2vec model.build_vocab(sentences_cut,update=True) #注意update = True 这个参数很重要 model.train(sentences_cut,total_examples=model.corpus_count,epochs=10) print(model) model.build_vocab(sentences_cut,update=True)新增词汇训练模型,得到新的模型。旧模型Word2Vec(vocab=122, size=256, alpha=0.025),新模型Word2Vec(vocab=149, size=256, alpha=0.025)。 三、模型常用API model.init_sims(replace=True)模型锁定,可以提高模型和后续任务的速度,同时也使得模型不能训练了,read only! vectors = model.wv.vectors 获取模型中全部的词向量 words = model.wv.index2word 获取模型中全部的词 可以看到加载模型后,每个向量以及全部词的结果,如下图所示:现在要获取词向量,直接使用 vec = model['生物医药'] print(vec) 一般都是使用word2vec来计算文本相似度,这里介绍几个常用的文本相似度的API #Compute the Word Mover's Distance between two documents. #计算两个文档的相似度——词移距离算法 model.wv.wmdistance() # Compute cosine similarity between two sets of words. # 计算两列单词之间的余弦相似度——也可以用来评估文本之间的相似度 model.wv.n_similarity(ws1, ws2) #Compute cosine similarities between one vector and a set of other vectors. #计算向量之间的余弦相似度 model.wv.cosine_similarities(vector_1, vectors_all) #Compute cosine similarity between two words. #计算2个词之间的余弦相似度 model.wv.similarity(w1, w2) #Find the top-N most similar words. # 找出前N个最相似的词 model.wv.most_similar(positive=None, negative=None, topn=10, restrict_vocab=None, indexer=None) 四、文本相似度计算——文档级别文本相似度的计算可以分为词、句子、段落和全文这几个层次,全文级别的也就是文档级别的。文档级别的相似任务,作为一个新入坑的小白,很容易就想到这样一条思路:对文档提取关键词,然后计算关键词之间的词移距离。这里面涉及到分词、关键词提取、关键词个数的选择等技术细节,最后还涉及到词移距离的计算,关键词的权重(重要程度)是否带入计算中。这里不考虑很多技术细节,仅仅把提取好的关键词做一个词移距离计算,展示一下gensim.model.word2vecmodelAPI的使用。 model.wv.n_similarity(ws1,ws2)数据如下: sent1 = ['奇瑞', '新能源', '运营', '航天', '新能源汽车', '平台', '城市', '打造', '技术', '携手'] sent2 = ['新能源', '奇瑞', '新能源汽车', '致力于', '支柱产业', '整车', '汽车', '打造', '产业化', '产业基地'] sent3 = ['辉瑞', '阿里', '互联网', '医师', '培训', '公益', '制药', '项目', '落地', '健康'] sent4 = ['互联网', '医院', '落地', '阿里', '健康', '就医', '流程', '在线', '支付宝', '加速']计算sent1和其他的相似度: t1 = time.time() model = Word2Vec.load('../model/word2vec.model') model.init_sims(replace=True) t2 = time.time() print(model) print('加载时间:%.4f' % (t2 - t1)) sent1 = ['奇瑞', '新能源', '运营', '航天', '新能源汽车', '平台', '城市', '打造', '技术', '携手'] sent2 = ['新能源', '奇瑞', '新能源汽车', '致力于', '支柱产业', '整车', '汽车', '打造', '产业化', '产业基地'] sent3 = ['辉瑞', '阿里', '互联网', '医师', '培训', '公益', '制药', '项目', '落地', '健康'] sent4 = ['互联网', '医院', '落地', '阿里', '健康', '就医', '流程', '在线', '支付宝', '加速'] sim1 = model.wv.n_similarity(sent1, sent2) sim2 = model.wv.n_similarity(sent1, sent3) sim3 = model.wv.n_similarity(sent1, sent4) print('sim1',sim1) print('sim2', sim2) print('sim3', sim3)用词移距离来度量的话: distance1 = model.wv.wmdistance(sent1,sent2) distance2 = model.wv.wmdistance(sent1,sent3) distance3 = model.wv.wmdistance(sent1,sent4) print(distance1) print(distance2) print(distance3)结果如下所示:
sim值越大文档的相似性就越高,distances的值越小就越相似。这种用关键词来衡量文档的相似度,用词移距离比用cos距离效果更好。在计算词移距离的时候,把关键词的权重引入,效果更好,但是计算是非常耗时的。
word2vec的基本知识目前我了解的就这么多了,以后懂的多了再来更新!
参考文章: NLP之——Word2Vec详解 word2vec两种训练方法 Word2Vec模型增量训练 |


【本文地址】